From LeetCode to Production: Turning a Simple Algorithm into a Full-Featured Project
From LeetCode to Production: Turning a Simple Algorithm into a Full-Featured Project
Ever faced one of those algorithmic interview questions that seems simple on the surface? That’s exactly where this journey began — with a basic LeetCode problem to find repeated characters in a string. But instead of stopping at the solution, I decided to transform it into a fully-featured, production-ready application.
The Original Problem: Finding Duplicate Characters
The original challenge was straightforward:
Problem: Given a string, find all characters that appear more than once.
Examples:
- Input: “banana” → Output: [“a”, “n”]
- Input: “hello world” → Output: [“l”, “o”]
The solution for this is simple — create a character frequency counter (a histogram) and then return characters that occur multiple times. The time complexity is O(n) where n is the length of the string, and the space complexity is O(k) where k is the number of unique characters.
def find_duplicates(text: str) -> list[str]:
histogram: dict[str, int] = {}
for ch in text:
if ch.isspace():
continue
histogram[ch] = histogram.get(ch, 0) + 1
return [ch for ch, cnt in histogram.items() if cnt > 1]
But what if we could make this simple solution more interesting? What if we could visualize those duplicates in a fun way?
Duplicate Letter Fest: Adding Fun to Algorithms
That’s how “Duplicate Letter Fest” was born — a CLI tool that not only finds duplicate characters but presents them with colorful ASCII balloon animations in your terminal. Each duplicate character gets its own balloon that floats up your screen!
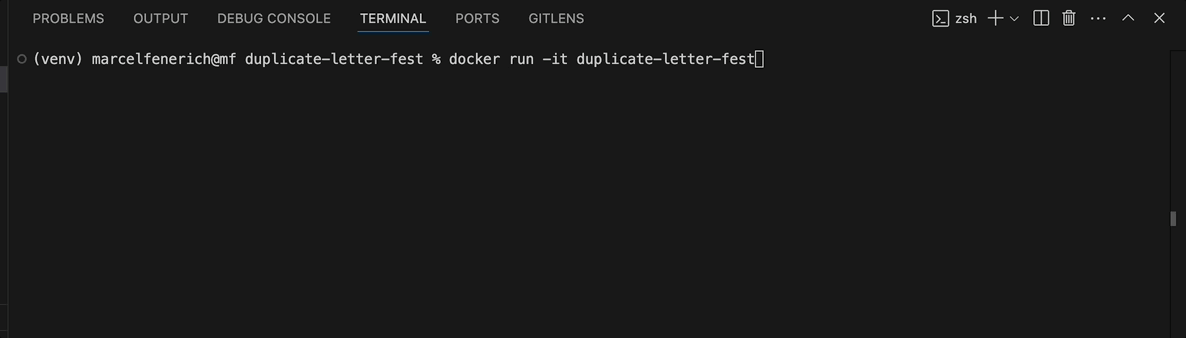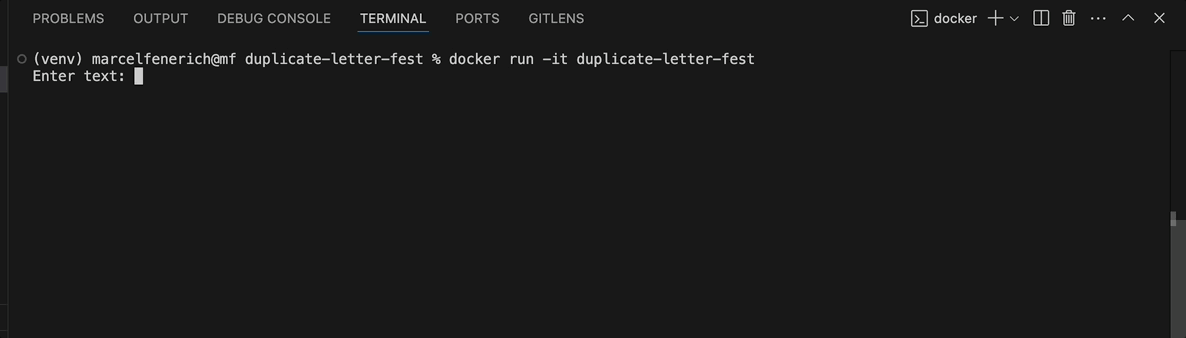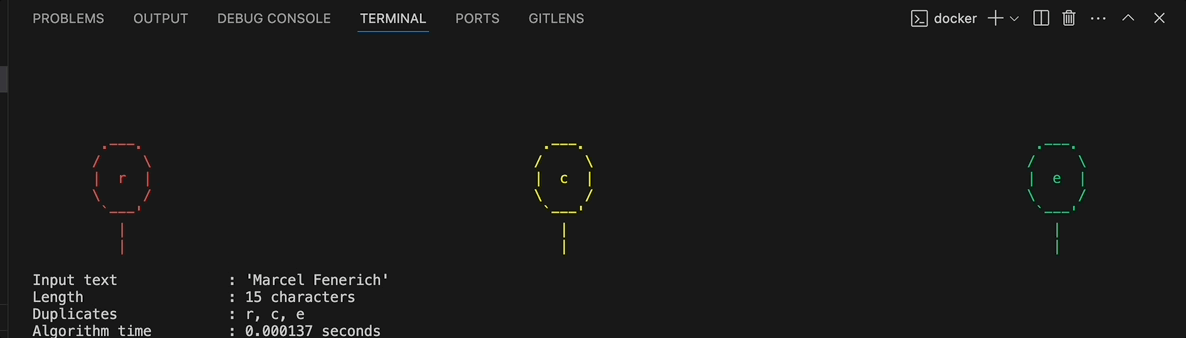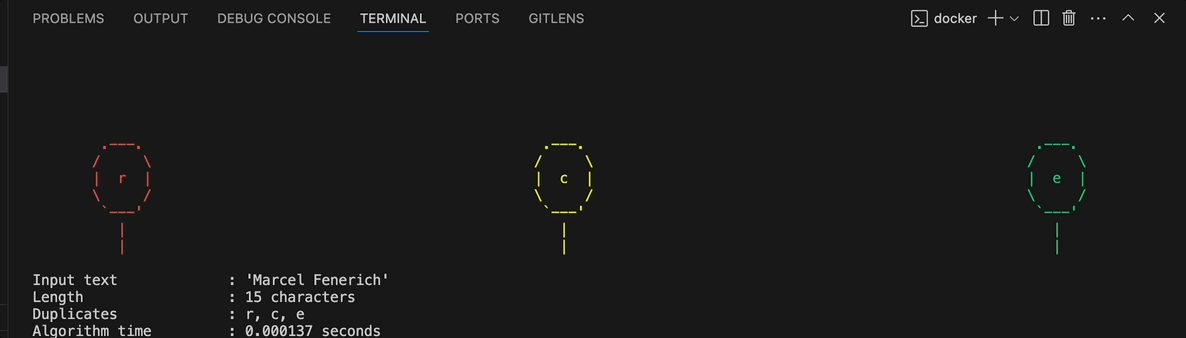
But I didn’t stop at just adding animations. I decided to apply professional software engineering practices to transform this simple algorithm into a production-quality project.
Applying Software Engineering Best Practices
1. Solid Architecture with SOLID Principles
The project follows the SOLID principles of object-oriented design:
- Single Responsibility: Each class has one job —
DuplicateFinderfinds duplicates,Visualizerhandles visualization, etc. - Open/Closed: The system is extensible without modification — we can add new visualization methods by implementing the
Visualizerinterface. - Liskov Substitution: Different implementations like
BalloonVisualizerandNoAnimationVisualizercan be used interchangeably. - Interface Segregation: Interfaces are focused and minimal.
- Dependency Inversion: High-level modules depend on abstractions, not concrete implementations.
The code is organized into logical modules with clear separation of concerns:
src/
├── __init__.py
├── main.py # Entry point
├── cli/ # Command-line interface
│ ├── __init__.py
│ └── parser.py
├── core/ # Core functionality
│ ├── __init__.py
│ ├── duplicate_finder.py
│ └── result.py
├── profiling/ # Performance measurement
│ ├── __init__.py
│ └── memory_profiler.py
└── ui/ # User interface
├── __init__.py
├── visualizer.py
└── balloon_viz.py
2. Type Safety
The entire codebase is annotated with proper type hints, making it more maintainable and less prone to runtime errors:
def process_input(
input_text: str,
finder: DuplicateFinder,
visualizer: Visualizer,
profiler: Optional[MemoryProfiler] = None,
) -> None:
# ...
And with a strict mypy configuration, any potential type issues are caught before they reach production.
3. Comprehensive Testing
The project includes a full test suite using pytest with parameterized tests:
@pytest.mark.parametrize(
"input_text,expected",
[
("", []),
("banana", ["a", "n"]),
("a b a", ["a"]),
("AaAa", ["A", "a"]),
],
)
def test_histogram_duplicate_finder(input_text: str, expected: list[str]) -> None:
finder = HistogramDuplicateFinder()
assert finder.find_duplicates(input_text) == expected
4. CI/CD Pipeline
GitHub Actions workflows ensure code quality on every push and pull request:
name: Code Quality
on: [push, pull_request]
jobs:
lint:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Set up Python
uses: actions/setup-python@v5
with:
python-version: '3.9'
# ... more setup and execution steps
5. Code Quality Tools
The project enforces consistent code style and quality with:
- Black: Uncompromising code formatting
- isort: Import sorting
- flake8: Style guide compliance
- pre-commit hooks: Automated checks before commits
6. Containerization with Docker
FROM python:3.9-slim
# Set working directory
WORKDIR /app
# Copy requirements first for better caching
COPY requirements.txt .
# Install dependencies
RUN pip install --no-cache-dir -r requirements.txt
# Copy application code
COPY . .
# Set environment variables
ENV PYTHONUNBUFFERED=1
ENV PYTHONDONTWRITEBYTECODE=1
ENV TERM=xterm-256color
# Run the application
ENTRYPOINT ["python", "-m", "src.main"]
Advanced Features Beyond the Original Problem
1. Memory Profiling
The application includes optional memory profiling to track how much memory the duplicate-finding algorithm uses:
class MemoryProfiler:
def start(self) -> None:
tracemalloc.start()
def stop(self) -> MemoryStats:
current, peak = tracemalloc.get_traced_memory()
tracemalloc.stop()
return MemoryStats(current, peak)
2. Terminal Animation Using Curses
The balloon animation uses the curses library for flicker-free terminal rendering:
def _animate_balloons(
self, stdscr: CursesWindow, positions: List[Tuple[int, int, str, int]]
) -> None:
max_y, max_x = stdscr.getmaxyx()
for step in range(self.height):
stdscr.erase()
for y0, x0, ch, idx in positions:
y = y0 - step
color_pair = curses.color_pair((idx % 5) + 1)
for dy, line in enumerate(BALLOON_ART):
if 0 <= y + dy < max_y and 0 <= x0 < max_x:
stdscr.addstr(y + dy, x0, line.format(ch), color_pair)
stdscr.refresh()
time.sleep(self.float_time)
3. Flexible CLI Interface
The application provides a rich set of options for configuring the behavior:
-v, --verbose : Show debug logs of histogram counts
--fast : Decrease animation delay for faster floats
--height N : Set number of animation steps (default: 12)
--no-animation : Skip animations and print summary only
--mem-profile : Report memory usage of the duplicate-finding step
--input-file FILE : Process multiple inputs from FILE
Lessons Learned
Taking a simple algorithm and transforming it into a full-featured project taught me several important lessons:
-
Start Simple, Expand Gradually: Beginning with a core algorithm that works correctly provides a solid foundation for adding features.
-
Abstractions Matter: Proper interfaces and abstractions make extending the codebase much easier.
-
Tests First: Having a comprehensive test suite gave me confidence when refactoring and adding new features.
-
DevOps from the Start: Implementing CI/CD early helped catch issues before they became problematic.
-
Documentation is Crucial: Good documentation (like the README.md) helps others understand your project quickly.
Conclusion
What started as a simple LeetCode problem to find duplicate characters in a string evolved into a full-featured application with animations, comprehensive testing, CI/CD integration, and more. This demonstrates how applying software engineering best practices can transform even simple algorithms into robust, production-ready applications.
The next time you solve a coding challenge, consider taking it further — it’s a great way to practice real-world software engineering skills while creating something fun and useful.
The complete source code for this project is available on GitHub: Duplicate Letter Fest
Feel free to try it out, contribute, or use it as inspiration for your own projects!